
Stell dir vor, ein geschäftskritisches System läuft nicht rund. Nutzende melden Performance-Probleme: Einige Dienste reagieren verzögert, andere funktionieren gar nicht mehr, doch du hast keine klare Antwort auf die Frage: „Was ist hier das Problem?“
Ein IT-Überwachungssystem sollte sofort identifizieren oder mittels Machine Learning sogar vorhersagen können, wo es in der Systemlandschaft hakt. Trotzdem lassen sich fast überall dieselben Szenen beobachten: Stunden werden mit Problemanalysen verbraten, Verantwortlichkeiten werden hin- und hergeschoben, bis schlussendlich unter hohem Frust gerade so die Ursache gefunden werden konnte.
In diesem Beitrag erfährst du mehr über die Grundprinzipien für erfolgreiches Monitoring und wir skizzieren unsere kosteneffiziente, automatisierte und skalierbare Monitoring-Lösung für Unternehmen jeder Grösse und Branche.
Die Grundpfeiler der Observability
Alleinstehende Datenpunkte liefern wertvolle Informationen, doch können selten ganzheitliche Aussagen abbilden. Um den vollen Wert von Telemetriedaten auszuschöpfen, müssen wir zuerst verstehen, welchen Zweck sie erfüllen.
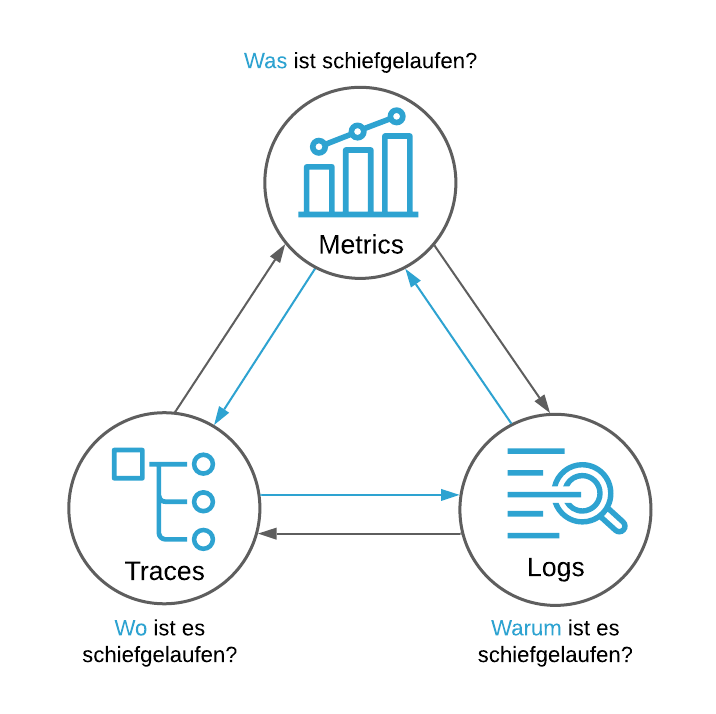
Stell dir ein Auto vor:
Metriken: Eine Vielzahl von Sensoren im Fahrzeug erfassen laufend Daten wie Geschwindigkeit, Motortemperatur und Benzinstand. Diese Daten sollen den aktuellen Zustand des Fahrzeugs überwachen.
Logs: Detaillierte Fehler-Meldungen und Fehler-Codes werden in der Garage ersichtlich, nachdem das Fachpersonal den Fehlerspeicher des Fahrzeugs ausgelesen hat. Es bietet eine chronologische Aufzeichnung über Vorkommnisse und deren Begründungen.
Traces: Ein GPS zeichnet den genauen Weg und die Position des Autos auf, einschliesslich der Dauer jeder Fahrt und der zurückgelegten Route. Diese Daten geben Auskunft über Ort und Zeitpunkt eines Ereignisses.
Daten sind gut, Zusammenhänge sind besser
Effiziente Systemüberwachung beinhaltet nicht nur das Sammeln von Daten, sondern das Stellen von wichtigen Fragen.
- Wie hängen meine Systeme zusammen?
- Welche Teilkomponenten können einen Einfluss auf die Performance meiner Systeme haben?
- Welche Indikatoren weisen auf mögliche Probleme hin?
Die Antworten auf diese Fragen helfen dabei, die richtigen Daten zu kombinieren und Probleme schnell zu identifizieren. Der Schlüssel liegt in der gezielten Darstellung relevanter Informationen auf anwendungsspezifischen Dashboards und der sofortigen Alarmierung, sobald kritische Schwellwerte überschritten oder unterschritten werden.
Um zum Beispiel des Autos zurückzukommen, sprechen wir in diesem Fall vom Armaturenbrett. Hier werden für den Fahrer unmittelbar relevante Daten, wie die aktuelle Geschwindigkeit oder die Motortemperatur angezeigt. Zudem wird ein Alarm ausgelöst, wenn unter anderem der Benzinstand zu niedrig oder der letzte Service zu lange her ist. So wird der Fahrer auf Probleme aufmerksam gemacht, bevor sie überhaupt eintreten. Natürlich wären noch viel mehr Metriken, wie die aktuelle Drehzahl der Räder oder der Stromverbrauch des Bordcomputers verfügbar, sind jedoch in diesem Kontext völlig irrelevant.
Observability muss nicht teuer sein
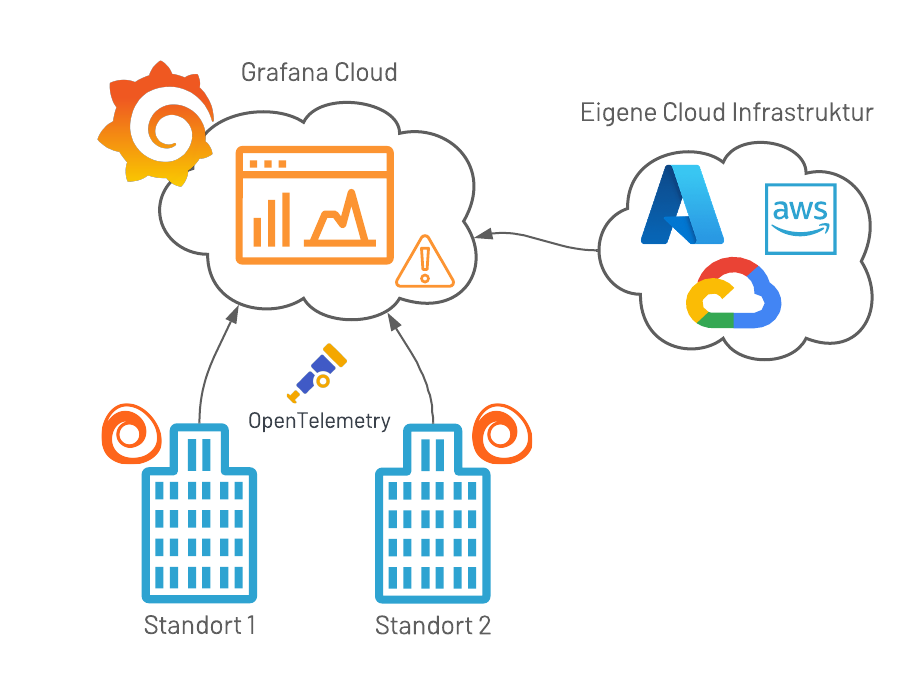
Umfassende Monitoring-Lösungen sind oft mit erheblichen Kosten verbunden. Im Zeitalter der Cloud und flexiblen Preismodellen gibt es allerdings preiswerte und zukunftssichere Alternativen. Dank der neuesten Entwicklungen in Standards wie «OpenTelemetry» können Metriken, Logs und Traces zentral gesammelt und in skalierbare Cloud-Umgebungen übertragen werden. Durch Automatisierung lassen sich Konfigurationen dynamisch erweitern und anpassen, sodass Visualisierungen, Alarme und die unterliegende Infrastruktur effizient verwaltet werden können. Das reduziert die Komplexität der Systeme, die für das Sammeln und Verarbeiten von Daten erforderlich sind.
Fazit
Eine gute Monitoring-Strategie spart nicht nur Zeit bei der Fehlersuche, sondern ermöglicht durch Predictive Maintenance, potenzielle Probleme frühzeitig zu erkennen, ähnlich wie ein Wetterbericht. Durch Automatisierung müssen Administratoren weniger Hand anlegen und die Verwendung von Cloud-Diensten reduziert zeitintensive Wartungsarbeiten. Eine gut durchdachte Alarmierung trägt zur effektiven Fehlersuche bei und verhindert, dass Sensoren aus Frust einfach deaktiviert werden.
Auch führende Unternehmen und Fachstellen in der Technik-Branche sind sich einig: Observability wird in Zukunft immer wichtiger, weil unsere Infrastruktur immer komplexer wird.
«75 % der TechnologiespezialistInnen weltweit geben an, dass die IT-Komplexität heutzutage größer ist als je zuvor.» (Cisco)
«Key innovations: AI/ML-driven insights, predictive analytics, data visualization, intelligent automation, cloud visibility, ease of use, open source, APIs» (IDC)
Wir bieten eine ganzheitliche Observability-Lösung, die Metriken, Logs und Traces vereint und zentrale Daten-Speicherung und -Aufbereitung in der Grafana Cloud in den Fokus rückt. Das Anwendungsgebiet geht weit über IT-Systeme hinaus und lässt sich auch hervorragend für Business-Intelligence nutzen. Unsere Expertise hilft dir, Daten richtig zu interpretieren, Automatisierung effizient einzusetzen und dein Team optimal zu schulen. Möchtest du mehr erfahren? Dann freuen wir uns, von dir zu hören!